PADRÃO PAGE OBJECT (POM)
TLDR (Muito Longo, Não Li)
Opções de estrutura de projeto:
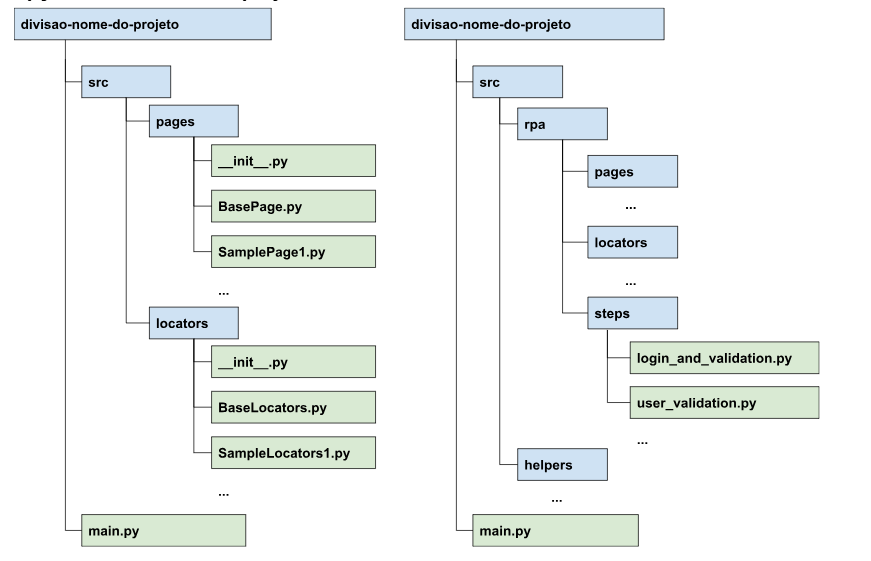
Modelo de arquivo Page: SamplePage.py
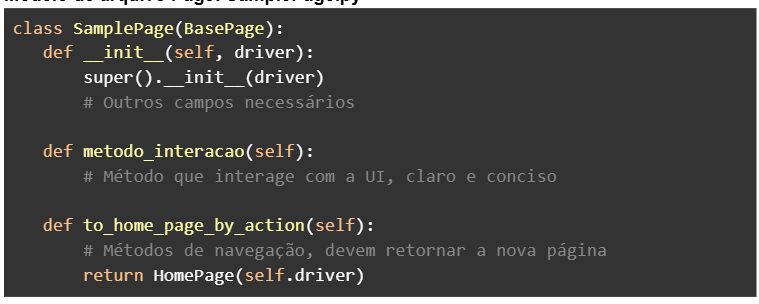
Modelo de arquivo de Locator: SampleLocator.py


Sobre o Padrão
O Padrão Page Object (Page Object Model - POM) combina técnicas do Selenium juntamente com a Programação Orientada a Objetos para tentar minimizar o tempo de troca de contexto na escrita e manutenção de códigos referentes a projetos de Automação de Processos (RPA).
O padrão será adotado no time através de 3 estágios sucessivos:
Aplicação do padrão em novos projetos. Aplicação do padrão na reformulação de projetos antigos que precisarem de manutenção intensa. Reformulação de projetos antigos para mandar a base de código padronizada.
Este documento irá trazer guias e informativos entre eles:
- Como, onde e quando aplicar esse modelo
- Padrões e Antipadrões referentes ao modelo
- A estrutura geral de um projeto que utiliza o POM
- Como resolver problemas recorrentes durante a aplicação do modelo
- Boas práticas e técnicas sugeridas
E outros que serão adicionados conforme analisada a necessidade de documentação.
A maioria das técnicas abordadas neste documento, irão focar, mas não se restringem, na aplicação do modelo POM em projetos de RPA desenvolvidos na linguagem Python utilizando a biblioteca Selenium.
Estrutura de pastas do Padrão
A estrutura de pastas de um projeto que utiliza o padrão Page Object não difere muito da estrutura normal de um projeto RPA, apenas apresenta um nível de organização diferente.
Por exemplo, em um projeto simples que utilize o padrão Page Object, a estrutura de pastas referentes ao código fonte é dada da seguinte maneira:
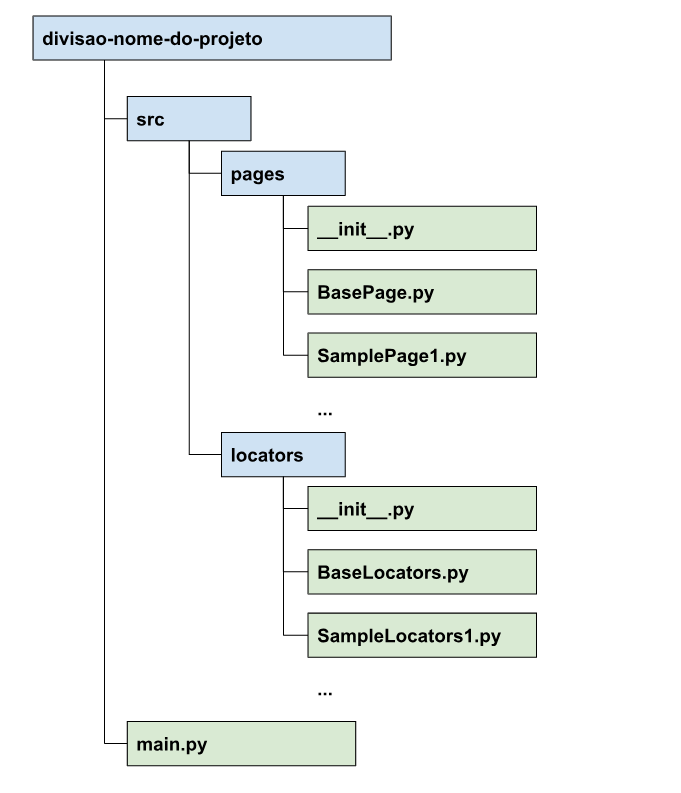
Em projetos mais complexos que possua bastante lógica de programação que não seja diretamente vinculada a código de interação com interfaces de usuário (processamento de dados, acesso ao banco, manipulação de arquivos, conexões com API, etc.) a estrutura pode ser adaptada e seguir o seguinte modelo, ainda semelhante ao anterior:
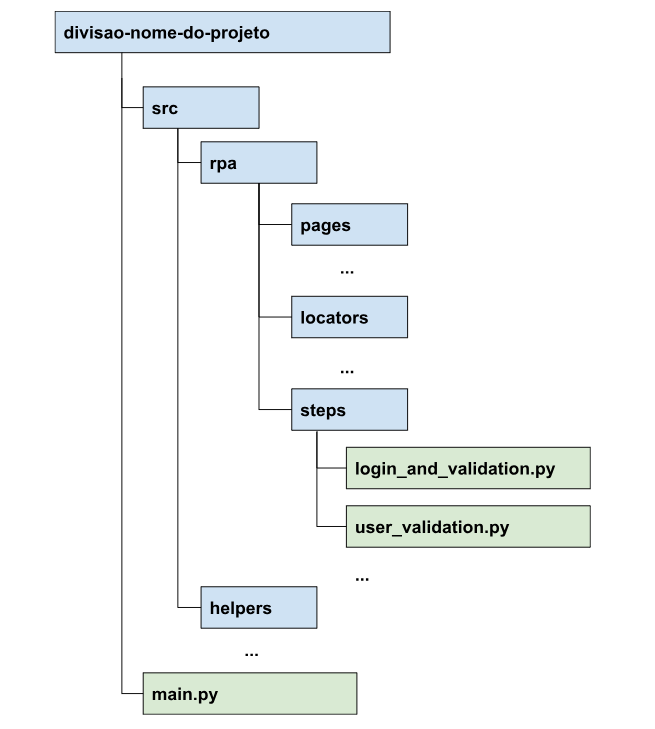
Ou seja, segue-se o mesmo padrão de projeto que tínhamos antes, porém, neste modelo colocamos todo o código que faz ações diretamente vinculadas com interação com o RPA dentro de uma pasta com nome rpa, enquanto outros códigos estarão dentro de outras pastas como já é o caso dentro dos projetos do GAB com a pasta helpers, utils, etc.
Afinal, fica a critério do desenvolvedor decidir qual o tipo de padrão que será utilizado na nomenclatura das pastas. Deve-se atentar apenas ao uso de duas pastas obrigatórias:
- A pasta pages contendo o arquivo BasePage.py
- A pasta locators
Estrutura de arquivos do Padrão:
Arquivos de Página (Page):
Os arquivos de página devem seguir certas convenções:
-
Devem estar dentro da pasta pages
-
A nomenclatura do arquivo deve seguir o padrão camelCase, deve terminar com Page e deve começar com letra maiúscula. ex: Para uma página de login, tente LoginPage.py
-
Cada arquivo deve possuir exatamente uma classe, onde:
-
O nome da classe deve ser exatamente igual ao nome do arquivo ex: O arquivo LoginPage.py deve ter a classe LoginPage
-
A classe deve herdar da classe BasePage (disponível)
-

Dentro da pasta pages, cada arquivo deverá representar uma Página da sua automação. Por exemplo: se sua automação consiste em:
- Ler uma planilha do excel
- Abrir um site na tela de Login
- Fazer login e navegar para a tela de Início
- Navegar para uma tela de Consulta
- Realizar consultas e efetuar logout, voltando para a tela de login
- Processar dados lidos pela tela de Consulta e enviar emails
Então podemos ver que os passos 1 e 6 não serão representados por uma Página no nosso modelo. Porém, os passos 2, 3, 4 e 5 nos darão:
- LoginPage: Decorrente da tela de Login (passos 2 e 5)
- HomePage (ou InicioPage): Decorrente da tela de Início (passo 3)
- SearchPage (ou ConsultaPage): Decorrente da tela de Consulta (passos 4 e 5)
OBS: Muitas vezes podemos encontrar iFrames dentro de páginas, e em alguns casos muito específicos esses iFrames podem ser corretamente modelados como páginas. Entretanto, isso só é o caso se aquele iFrame é independente da página que o contém, e pode ser interpretado como uma página isolada, tendo seu próprio arquivo de página. Entretanto, vale lembrar que esse tipo de situação não é muito comum. Para analisar se é necessário modelar um iFrame como uma página, faça a seguinte pergunta:
“Visualmente, o site parece ter outro site dentro dele?”
Se a resposta for sim, então provavelmente você poderá modelar o iFrame como uma página. Senão, o iFrame fará parte da página que o contém.
Dentro de uma classe de página, temos 3 tipos de métodos que podem existir dentro deles:
Método Construtor:
O método construtor é obrigatório e deve estar presente em toda classe de páginas. Esse método é chamado sempre que uma classe da página é instanciada, e deve, obrigatoriamente, chamar o construtor de BasePage, através de uma chamada super().
O método construtor é bem simples e deve ter um modelo como o abaixo:

Em alguns casos, pode ser vantajoso armazenar uma informação que será utilizada comumente em todo o método. Nesse caso, informações adicionais podem ser passadas ao construtor para fácil acesso, como por exemplo:

Métodos de interação:
Constituem a grande maioria dos métodos presentes em classes de páginas. Eles condensam interações concisas na interface de usuário. Estes métodos devem ser simples e diretos ao ponto, evitando fazer muitas coisas em um método só. Alguns exemplos de métodos de interação são:
- Clicar em um botão
- Preencher um campo de formulário
- Fazer upload de um arquivo
OBS: Tente deixar a complexidade de suas funções baixas. Lembre-se:
“Funções devem ser claras e concisas. Elas devem responder a uma pergunta, ou realizar uma ação, mas não ambas ao mesmo tempo.”
Um bom exemplo é a ação de fazer login. Ao invés de criar uma função que faz o login, podemos “quebrar” a lógica dessa função em pequenas partes:

Desse modo, conseguimos isolar melhor os erros que podem vir a acontecer, diminuir o tempo de troca de contexto e facilitar a manutenção de código ao longo do tempo.
Porém, isso é apenas uma sugestão de como modelar seu RPA. Existem inúmeras formas de resolver o mesmo problema, não se sinta desencorajado em criar uma modelagem de solução que faça sentido para o contexto do seu problema.
Métodos de navegação:
Estes métodos representam ações que fazem o robô navegar de uma página para outra. Eles tem uma convenção de nomenclatura.
to_<NOME_DA_PAGINA_EM_SNAKE_CASE>
Se desejar, pode ainda especificar que tipo de ação está sendo feita para motivar a navegação:
to_<NOME_DA_PAGINA_EM_SNAKE_CASE>_by_<AÇÃO>
Por exemplo, se um método navega de uma página para uma página principal, temos:

Se gostaríamos de especificar ainda que, essa navegação é motivada pois o usuário se autenticou da página, podemos ter:

Outro ponto muito importante de se destacar é que, como métodos de navegação trocam a página em que estamos realizando ações, esses tipos de método devem retornar uma nova página. Por exemplo, suponha que temos duas páginas: LoginPage e HomePage. Um método que navega da LoginPage para HomePage deverá estar contido LoginPage e ter o seguinte retorno:

Como todo construtor de página precisa de um driver, passamos o driver da página atual (através de self.driver) para a nova página, transferindo o estado da aplicação.
Arquivos de Localizadores (Locators):
Os arquivos localizadores servem para armazenar quaisquer tipos de constantes que possam estar associadas a uma ou mais páginas na nossa aplicação. O termo Locators pode ser traduzido para Localizadores e é originado diretamente do Selenium.
Um Locator é sempre composto por uma** par ordenado** (também conhecido como uma tupla de 2 elementos) da seguinte forma:
( <MÉTODO_DE_LOCALIZAÇÃO> , <IDENTIFICADOR> )
<MÉTODO_DE_LOCALIZAÇÃO>: Indica como que iremos localizar certo elemento. Pode ser por ID, nome de Classe, nome da Tag, XPATH, etc. Todo método de localização disponível para nós está localizado no módulo By em selenium.webdriver.common.by
Uma lista completa com os métodos de localização disponíveis pode ser encontrada aqui.
<IDENTIFICADOR>: Uma vez descrito como vamos encontrar certo elemento, precisamos agora saber que tipo de informação estamos procurando. Ou seja, se estamos procurando um elemento pelo seu ID, informamos através do identificador qual ID estamos procurando.
Uma vez entendido que tipos de localizadores podemos ter em uma aplicação, as classes Locators são utilizadas para armazenar todos os localizadores que são utilizados em uma página.
Os arquivos de Locators devem seguir certas convenções:
-
Devem estar dentro da pasta locators
-
A nomenclatura do arquivo deve seguir o padrão camelCase, deve terminar com Locators e deve começar com letra maiúscula. -ex: Para os localizadores de LoginPage, tente LoginLocators.py
-
Cada arquivo deve possuir exatamente uma classe, onde:
-
O nome da classe deve ser exatamente igual ao nome do arquivo
- ex: O arquivo LoginLocators.py deve ter a classe LoginLocators
-
Cada propriedade desta classe deverá representar um Locator (ou, em outros casos, uma constante de String que é comumente utilizada na página) de modo que o nome das propriedades:
- Deve ser legível, conciso e descritivo
- Palavras diferentes devem ser separadas por underscore (‘_’)
- O nome deve ser composto apenas por caracteres maiúsculos
-

Usar localizadores desta forma diminui o risco de erros de digitação, centraliza os pontos de falha que podem ocorrer e facilitam a identificação e manutenção do código.Para utilizar os localizadores na página correspondente, basta importá-los na página apropriada. Uma sugestão de importação segue abaixo:

Como uma página só deve usar localizadores daquela página em específica, a sintaxe acima importa os localizadores apenas como Locators, para uma mais fácil leitura.
Se duas ou mais páginas usam localizadores compartilhados, considere usar um arquivo de localizadores compartilhados, denominado SharedLocators.py. Esse arquivo segue todas as recomendações de localizadores normais.

Recomenda-se entretanto, diferenciar a importação entre os localizadores normais e localizadores compartilhados:

Arquivos Principais (main.py, rpa.py, ...):
O padrão Page Object veio para organizar e facilitar o processo de desenvolvimento e manutenção de projetos dentro do Grupo Águia Branca, porém, ele não visa colocar mudanças nos outros arquivos que não estão diretamente relacionados com RPA. Uma exceção a isso são os arquivos que chamam as classes criadas, definindo o fluxo principal da automação.
Como mencionado anteriormente, o fluxo da aplicação pode estar contido de maneira centralizada (no arquivo main.py ou rpa.py) ou de maneira descentralizada (dividido em etapas numa pasta steps entre várias etapas diferentes). Independente de como esses arquivos estejam dispostos, o fluxo geral de uma automação sempre segue alguns passos simples:
- Instanciação do driver com as configurações necessárias
- Navegação para a página principal da aplicação
- Instanciação da página inicial
- Execução de métodos de interação e navegação
- Encerramento do RPA
Vamos passar brevemente contendo exemplos de cada um desses passos:
-
Instanciação do driver com as configurações necessárias:
Embora já tenhamos alguns arquivos espalhados pelos projetos que fazem a configuração do webdriver, recomenda-se utilizar uma forma simples e customizável do mesmo, sendo que essas configurações geralmente mudam de projeto para projeto. Um exemplo da sua utilização é visto a seguir:
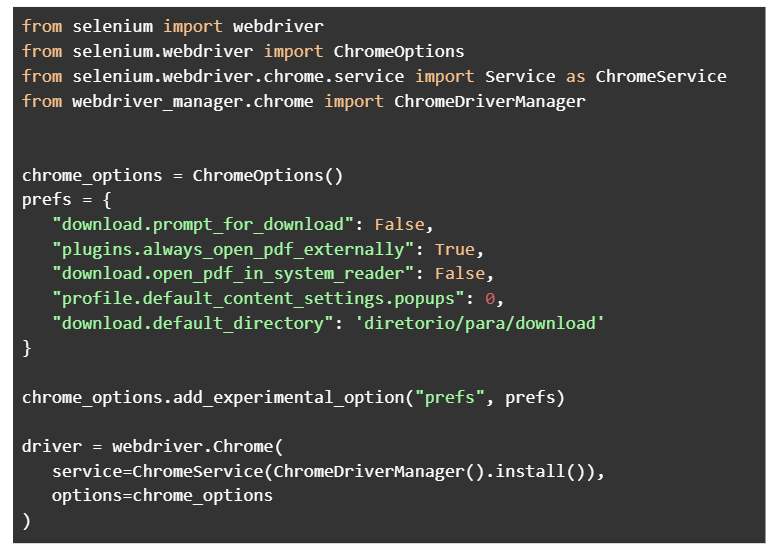
-
Navegação para a página principal da aplicação
Uma vez instalado o driver principal da aplicação, precisamos partir de uma página inicial da nossa aplicação. Esse processo pode ser feito fora do POM (que será mostrado abaixo) ou dentro do POM (dentro do construtor da primeira página, por exemplo). Isso fica a critério do desenvolvedor. Recomenda-se que, na primeira página, haja um método que navegue para a nossa página principal.
Continuando o exemplo, temos:
Exemplo: Fora do POM

Exemplo: Dentro do POM

-
Instanciação da página inicial
Quando navegamos para a página inicial da aplicação, precisamos agora criar o nosso primeiro objeto de página. Para isso, basta chamar o nosso construtor e alimentá-lo com o driver que criamos no passo 1.
Continuando o exemplo, assuma que partimos de uma página de login. Assim, temos:

-
Execução de métodos de interação e navegação
Uma vez criado nosso primeiro objeto de página, podemos seguir com o fluxo usando os métodos de interação e navegação daquela página para realizar todo o fluxo da automação. Vale lembrar que quando navegamos de uma tela para outra, nosso método de navegação vai nos retornar diretamente uma instância de outro elemento, assim, podemos salvar esse novo elemento em uma variável.
Consideremos no exemplo, um certo processo de Login, e depois de navegação para uma página de Home, e então, Consulta.
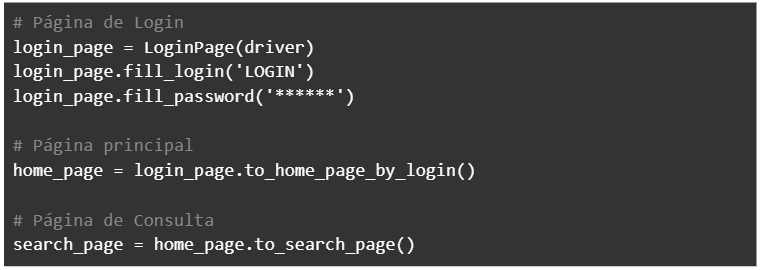
-
Encerramento do RPA
Após terminar todo o processo de automação que envolva interfaces de usuário, podemos finalizar o processo utilizando o driver. De modo semelhante ao passo 2, como implementar isso fica a cargo do desenvolvedor, podendo ser dentro ou fora do padrão Page Object.
Exemplo: Fora do POM
![]()
Exemplo: Dentro do POM

Problema conhecido: Import Circular
Em vários projetos RPA, é comum terminar na mesma página em que começamos. Basta visualizar um projeto simples onde começamos em uma página de Login, realizamos uma série de ações e finalizamos com uma ação de Logout que nos retorna para a página de Login. Quando isso acontece, podemos ver graficamente que telas importam quais telas:
Porém, como a página de Login retorna uma instância da página de Home, e assim sucessivamente até a página de SearchPage, que retorna uma instância da página de Login, cada página terá que importar a página para a qual ela irá fazer a transição. Porém, temos que:
- LoginPage precisa de HomePage
- HomePage precisa de ..., repetindo-se até chegar em SearchPage
- SearchPage precisa de LoginPage
Por transitividade, podemos concluir então que LoginPage precisa de SearchPage, e SearchPage precisa de LoginPage. Dependendo de como essas páginas foram importadas, podemos nos deparar com um erro a respeito de imports circulares (LINK).
Podemos consertar esse erro facilmente. Basta adotarmos uma convenção ao importar páginas. Ao invés de importar páginas da seguinte forma:

Para solucionar esse problema, importaremos as páginas da seguinte forma.

Isso se dá pela forma que o Python interpreta importações usando import ... em contraste com from ... import....
Documentação:
O fato do Padrão Page Object ser muito mais legível e organizado não é desculpa para não comentar os códigos escritos. Documentação é uma etapa muito importante e que afeta diretamente não só a qualidade do código, mas também facilita a manutenção e diminui o tempo de troca de contexto.
Faça suas documentações de maneira clara e bem descritiva. Se um método ou classe faz coisas demais, sua documentação pode ser muito longa e/ou de difícil leitura. Tome isso como um sintoma de que talvez seja necessário remodelar certas partes do código para que o mesmo fique mais claro e conciso.
Para documentar projetos que seguem o padrão page object, utilize a documentação em DocString do python, que pode ser encontrada aqui.
Projeto Template:
Um projeto de template, comentado e que aponta várias seções abordadas aqui pode ser encontrado aqui.